Lalal.ai Audio Splitter Review: Can You Split Mono Into Stereo?
Podcasters can’t always get what they want. Maybe you landed an interview with your dream guest, but only if you do it right here and now, and you don’t have your preferred recording equipment available. Maybe you have to record in a noisy environment, but you want to make sure your audiences can understand the voices. What’s a podcaster to do? Fortunately, there are software tools that can help. With Lalal.ai Audio Splitter software, we’ll separate the wheat from the chaff as best we can. Let’s see what artificial intelligence can do to salvage cluttered audio and clarify those voices.
How Does Lalal.ai Work?
Lalal.ai uses artificial intelligence to detect multiple sound sources (vocals and music) and split them into two separate sound files. The company was kind enough to send me a promotion code, so I could test the software’s features at all levels.
Signup is a little different, but still easy. You submit your email address to their website. Lalal.ai sends a link to your email address. Click on the link, and voilá, you’re signed up.
At their website, you drag the sound file you want to split and drop it onto the page to upload it.
Once it’s processed, you can listen to the split audio files and select how much processing you want: Free, Lite, or Professional.
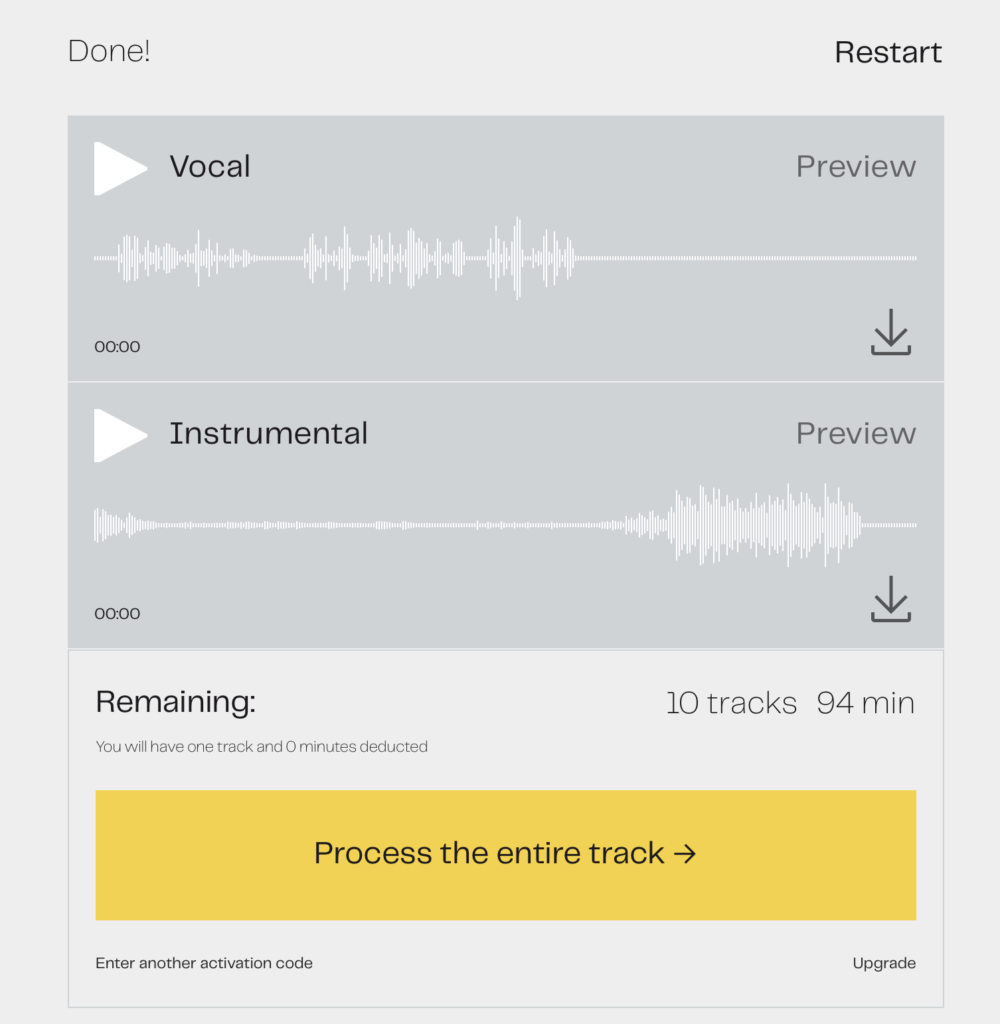
Lalal.ai Audio Splitter processes the file, splits the vocal from any background sounds, and displays two files for download: one marked vocal, the other marked instrumental. It takes only a few minutes, depending on how long your audio file is. Then you just click the down arrow to download the file.
Pricing
Lalal.ai audio splitter has three price tiers: Free, Lite, and Professional. Higher tiers let you have more flexibility, and use more data.
- Free: Users can upload and process up to ten minutes of audio (only) files up to 50 MB of data, in mp3, OGG or wav files.
- Lite: For $10, This tier lets users upload and split up to 90 minutes of 2 GB audio or video files. The acceptable file formats are MP3, OGG, WAV, FLAC, AVI, MP4, MKV, AIFF, and AAC. So, one can split audio or video. Lite has a faster processing queue, as well.
- Professional: For $20, users can upload and split up to 300 minutes of 2 GB audio or video files. This tier accepts the same file formats as Lite, and uses the same queue for faster processing.
Essentially, it’s reasonably priced and convenient. Let’s hear how it performs.
Samples of Audio Processed with Lalal.ai Audio Splitter software
Bear in mind that I know nothing about AI or machine learning, so I can’t begin to dissect this software. All I can describe is what I hear. What I tried is to;
- split a track into vocals and music
- split a track into two vocal tracks. This isn’t recommended on the web site, but I think podcasters would need this use.
Splitting audio and music
I started with a sample audio file I had lying around (as you do), from when I made screenshots for our GarageBand Podcast Production article.
I care about copyright, so here are the credits. Music is The Maple Leaf Rag by Scott Joplin, performed by Kevin McLeod. For more music, visit his website at incompetech.com. The joke is probably floating around in the zeitgeist, but I first heard it performed by Fozzie Bear on The Muppets. I know, when Matthew tests mics, he reads Beatrix Potter. I’ll try to step up my game for the next one.
Here’s what the vocal track sounds like, after processing it with Lalal.ai.
The background music is gone, mostly; I can still hear a tiny snippet of piano around the words. How’d the music turn out?
You probably remember from the Intro to Garageband article that I lowered the volume while I was speaking. That’s why you hear the volume get lower here, too, and then increase after I stopped talking. I notice that between seven and ten seconds, there’s almost an underwater sound, as if the software is trying to fill in notes that my voice covered up. So, yes, it’s music. But, I wouldn’t pick this out for karaoke night.
Splitting Vocals from Background Vocals
What about background voices? Let’s say you’re waiting in line for a ride at the carnival, and you notice The Dalai Lama is in line right behind you. You get him to agree to a quick interview for your podcast, in exchange for letting him budge ahead of you in line. But, all you have is your phone. Plus, a carnival isn’t exactly a silent home studio. What do you do?

For this example, I recorded myself telling the same horse joke, while holding my phone up playing a clip of the final speech from Charlie Chaplin’s seminal cinematic masterpiece, The Great Dictator.
You get the idea. if Selma and Patty were ahead of you in line yapping about funnel cake and their boyfriends, their voices would bleed into your recording. You don’t want that. Now, let’s see what happens when we try to split the vocal tracks, in this case, mine and Charlie’s.
Lalal.ai recognizes my voice as a voice. But, it recognizes anything other than the voice closest to the mic as an “instrumental.”
Lalal.ai did cut off the first 4 seconds of Chaplin’s speech (where Charlie talks about not wanting to be an emperor) before I started speaking. But, you can still hear his voice in and around my vocals. So, if you were trying to split primary vocals away from background sound, it can do it, mostly. But, you’ll still have artifacts.
Splitting Two Podcast Speakers into Two Tracks
I really thought the best use of this software would be to take a recording of two people, both on mics but recorded as one track, and split it into two tracks. So, Matthew and I had a quick Zoom call.
I could really benefit from Cleanvoice.ai. In any case, this is an example of the closest thing to a zero-effort podcast clip. Again, what I hoped to get was two vocal tracks, even if they were labelled Vocal and Instrumental.
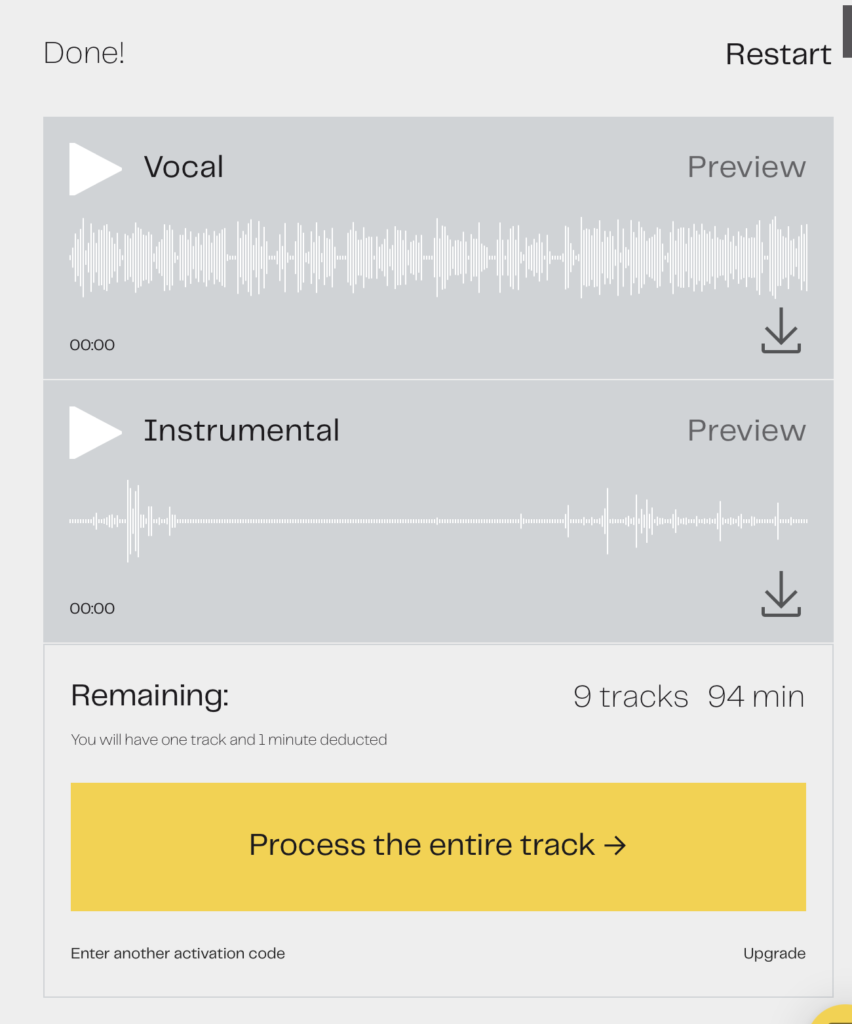
Look at the waveforms on these tracks. One takes up a lot of space, it’s loud and clear. The other one takes up hardly any space, it’s barely audible. I know Matthew’s quiet, but I’m not that much louder than him, am I?
Lalal.ai’s artificial intelligence solely looks for spoken language, as opposed to sounds other than verbal language. At least, that’s how it seems. We were both speaking, therefore our voices both went on the same track. As an example, Descript’s AI can detect the difference between spoken voices and transcribe what each speaker says. As transcription software, Descript does a good job of telling the difference between male and female voices, and differently-accented voices. So, this could have been a slam dunk. In this case, Lalal.ai is looking for two things: human voice, and not-human-voice.
To show you what the AI removed, here’s the “instrumental” track.
It seems like it extracted room noise (I had a fan running in the room), some bass frequencies, and a couple of mouth tics. This isn’t bad, necessarily, if you like experimental audio. I’m sure David Lynch would be very excited to hear the negative space of a conversation.
But I Really Want My Podcast In Stereo!
Again, I’m a writer, not a sound designer. Please bear in mind, we have resources that can help you get good audio for your podcast. Here are a few:
- Our Multitrack Recorder Guide,
- the Guide to Recording Two Mics Independently, With One Stereo Splitter,
- How to Split Sides of an Ecamm Skype Call recorder Interview,
- Our guide to the Best Call Recording Apps,
- and, What Are The Benefits of Double-Ender Recording?
There are better ways to achieve this result. I’m showing you this anyway, so you can see the idea. Here’s what I did.
I opened up Garageband as a vocal project, and made two tracks. Then, I took the .mp3 file of both Matthew and I talking, that Lalal.ai split from the room noise. I dragged & dropped it into each track, once. So, what you see here is the same file, copied and pasted into two different tracks.
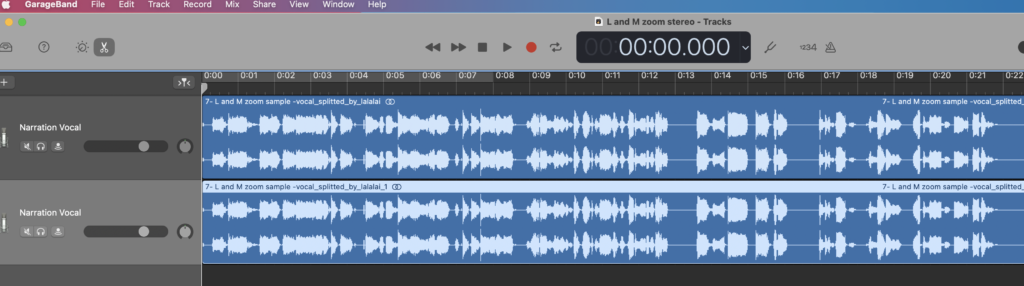
I renamed the tracks “Matthew” and “Lindsay,” respectively. Then, I used that little wheel to the right of the volume slider to pan Matthew’s vocal track hard to one side, and mine to the other.
Finally, I cut all of my voice out of Matthew’s track, and all of Matthew’s voice out of my track.
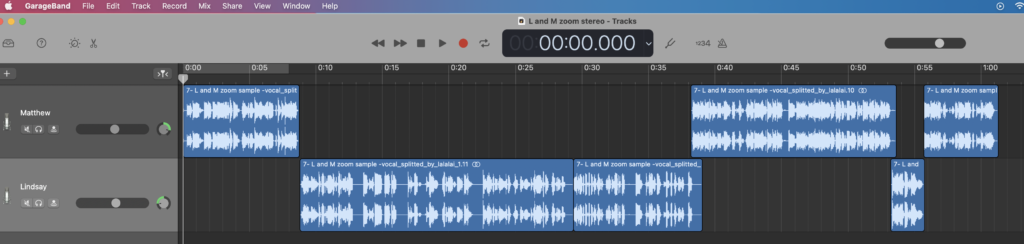
Not gonna lie, you’ll hear a couple of spots where we talk over each other a wee bit. More importantly, now that our voices are on separate tracks, I can process each differently. If you listen to this through headphones, it should sound more like stereo.
This isn’t “splitting,” in the sense that you break the track into two things. It’s copying, pasting, and cutting. But, this lets me dig in and give each track the settings that make Matthew and I both sound our best. At least, I would, were I an experienced sound designer.
Pros and Cons of the Lalal.ai Audio Splitter Software
If you need to remove extraneous background sound from a recording, Lalal.ai is quick and won’t cost much money, if any. Plus, it’s web-based, so you can use it pretty much anywhere that you have Internet access.
But, if you want to split one cluttered vocal track into two clean, separate tracks, and preserve the integrity of the sound, Lalal.ai isn’t the right choice.

There are lots of ways to kill background noise. You can find workarounds to split sides of the call. Call recorder software is improving. There are all kinds of workarounds for odd podcasting situations. Lalal.ai Audio Splitter might not be your best best, but it’s accessible, and won’t break the bank.
Part of the fun of podcasting is finding new strategies and using new tech to make it easier to get your story out into the world. That’s one of the reasons we created Podcraft Academy. We don’t want you to be stuck in a trial-and-error cycle. We test new gear, methods, and software, so you can more easily launch and grow your show. Not only that, but also, our all-in-one podcasting solution, Alitu, can help you record, edit, polish and publish your podcast, so you can focus on making great content and building relationships. Give it a try!
